[220130] JVM 튜닝 (작성중)
Table of Contents
1 소개
JVM 최적화라는 책을 기반으로 정리중…
2 성능이란
성능지표는 무엇이 있을까
- 처리율(throughput) : 일정 시간 동안 완료작 작업 단위 수 (동일 스펙에서 비교한다)
- 지연(latency) : 하나의 트랜잭션을 처리하는 데 소요된 시간.
- 용량(capacity) : 작업 병렬성의 총량, 동시 처리 가능한 작업 단위(트랜잭션) 개수
- 사용률(utilization) : 어떤 리소스(CPU, 메모리)를 많이 사용하는지 확인하여 리소스를 효율적으로 배치한다.
- 효율(efficiency) :
throughput / utilization같은 처리율을 적은 리소스로 달성한다면 효율이 높은 것이다. - 확장성(scalability) : 리소스 추가에 따른 처리율의 변화가 시스템의 확장성을 가늠하는 척도이다. (변화가 커야 좋은 것)
- 저하(degradation) : 부하가 증가할 때, 지연 혹은 처리율 측정값의 변화정도를 본다.
2.1 성능지표
2.1.1 성능 엘보
부하가 증가하면서 예기치 않게 저하가 발생한다. (지연수치가 급격하게 커진다는 둥)
2.1.2 암달의 법칙
암달에 따르면 근본적으로 확장성에는 제약이 따른다. 태스크를 처리할 때 프로세서 개수를 늘려도 실행 속도를 무한정 높일 수는 없다.
3 JVM 이야기
JVM 기술 스택의 구조를 이해하자.
3.1 인터프리팅과 클래스로딩
JVM은 스택 기반 해석머신이다. 레지스터는 없지만 일부 결과를 실행 스택에 보관하며, pop으로 맨 위에 쌓인 값들을 가져와 계산한다.
JVM인터프리터(해석기)의 기본 로직은, 평가스택에 중간값을 담고(push)
마지막에 실행된 명령어와 opcode(명령코드:기계어의 일부로서 수행할 명령어를 나타내는 부호)를
하나씩 순서대로 처리하는 while 루프 안의 switch문 이다.
java HelloWorld 를 수행하면 HelloWorld.class 에 있는 main() 이 진입점(entry point)가 된다.
제어권을 이 클래스로 넘겨야하기에 가상 머신이 실행되기 전에 이 클래스를 로드해야 한다.
3.1.1 클래스로더
이때 클래스로딩 메커니즘이 관여한다. 자바 프로세스가 새로 초기화되면서 사슬처럼 줄지어 연결된 클래스로더가 차례차례 작동한다.
- 클래스로더(부트스트랩)
부트스트랩 클래스 -> 자바 런타임 코어 클래스(8버전 이전에는
rt.jar파일에서 가져왔지만, 9부터는 런타임이 모듈화 되면서 클래스로딩 개념이 많이 바꼈다. 아마 java9 jigsaw 때문인듯 하다.)부트스트랩 클래스로더의 주임무는 다른 클래스로더가 나머지 시스템에 필요한 클래스를 로드할 수 있는 최소한의 필수 클래스(
java.lang.Object, Class, Classloader) 만 로드한다. (자바 클래스로더도 하나의 객체에 불과하다. 그래서 초기에 먼저 존재해야 한다. 안그러면 순환성 문제가 생성된다.) - 클래스로더(확장 클래스로더)
말그대로 확장할 때 쓴다. 네이티브 코드를 제공하고 기본 환경을 오버라이드할 수도 있다. (잘 안쓰는 듯)
- 클래스로더(애플리케이션 클래스로더)
지정된 클래스패스에 위치한 유저 클래스를 로드한다.
프로그램 실행 중 처음 보는 새 클래스를 디펜던시(dependency)에 로드한다. 클래스를 찾지 못한 클래스로더는 부모 클래스에게 룩업을 요청한다. 계속 올라가서 못 찾으면 마지막으로 부트스트랩에게까지 올라간다. 그래도 못찾으면
ClassNotFoundException예외가 난다.한 시스템(프로그램)에서 클래스는 (패키지명을 포함한) 풀 클래스명과 자신을 로드한 클래스로더, 두 가지로 식별된다.
3.2 바이트코드 실행
javac 는 자바 코드를 .class 로 바꾼다. javap 같은 역어셈블리 툴로 쉽게 알 수 있다.
바이트코드는 특정 컴퓨터 아키텍처에 특정하지 않은 중간 표현형(Intemediate Representation, IR) 이다.
아래 자바 코드를 컴파일 해보자.
public class HelloWorld {
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
System.out.println("Hello World");
}
}
}
javap -c HelloWorld 를 수행해보자. (-v 옵션을 추가하면 클래스 파일 헤더 전체 정보, 상수 풀 세부 정보 등을 볼 수 있음)
public class HelloWorld {
public HelloWorld();
Code:
0: aload_0 // this 레퍼런스를 스택 상단에 올려놓는다.
1: invokespecial #1 // Method java/lang/Object."<init>":()V
2: return
public static void main(java.lang.String[]);
Code:
0: iconst_0 // int 상수 0을 평가 스택에 push
// 메소드가 실행되면 local variables 배열에 지연변수가 지정된다.
// 오프셋이 0은 this를 말하는 듯
1: istore_1 // push한 상수를 local variables의 오프셋 1(루프의 i)에 저장한다.
2: iload_1 // 오프셋 1의 변수를 스택으로 다시 로드
3: bipush 10 // 상수 10을 스택에 푸시한다.
5: if_icmpge 22 // 푸시된 값을 이용해서 비교를 한다.
8: getstatic #2 // Field java/lang/System.out ...
11: ldc #3 // String Hello World (상수 풀에서 "Hello World" 로드함)
13: invokevirtual #4 // Method java/io/PrintStream.println ...
16: iinc 1, 1 // 1 증가
19: goto 2 // 2번으로 다시 가기.
22: return
}
3.3 핫스팟 입문
핫스팟은 프로그램의 런타임 동작을 분석하고 성능에 가장 유리한 방향으로 영리한 최적화를 적용하는 가상 머신이다.
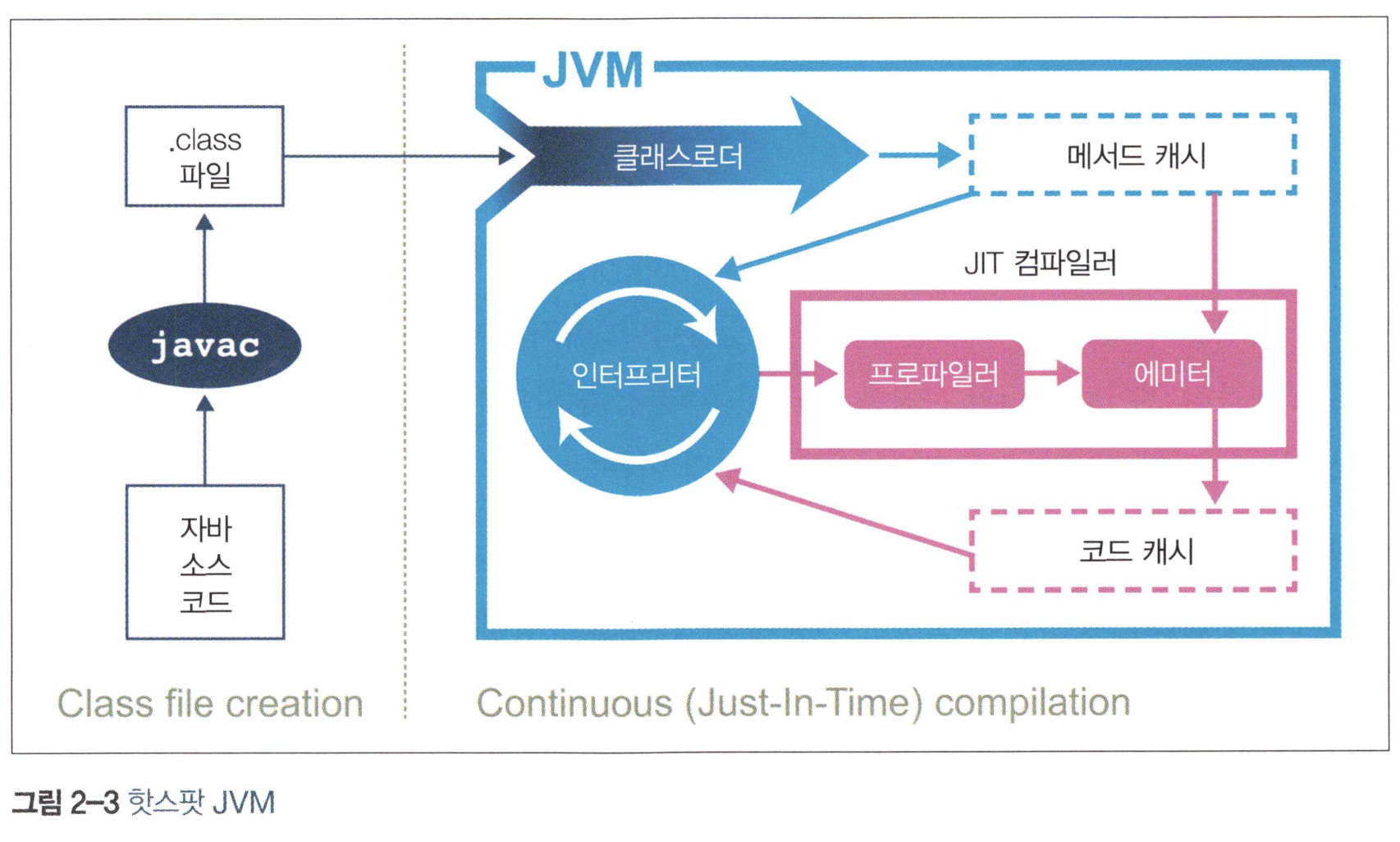
Figure 1: Hotspot Image
3.3.1 JIT 컴파일러
자바 프로그램은 (위에서 설명했지만) 인터프리터가 가상화한 스택 머신에서 명령어를 실행하며 시작된다. CPU를 추상화한 구조라서 여러 플랫폼에서 실행할 수 있지만, 성능을 최대로 내려면 네이티브 기능을 활용해 CPU에서 직접 프로그램을 실행시켜야 한다.
이를 위해 핫스팟은 프로그램 단위(메서드와 루프)를 인터프리티드 바이트코드에서 네이티브 코드로 컴파일한다. 이것을 JIT(Just-in-Time) 컴파일이라고 한다.
핫스팟은 인터프리티드 모드로 실행하는 동안 애플리케이션을 모니터링하면서 자주 실행되는 코드 파트를 찾아서 JIT 컴파일을 수행한다. JIT 방식의 큰 장점은 컴파일러가 해석 단계에서 수집한 추적 정보를 근거로 최적화를 결정한다는 것이다.
AOT(Ahead of Time)와 다른점이 뭐냐고 물어볼 수 있다. AOT는 프로세서와 상관없이 중간 언어(바이트코드)로 배포를 하고 실행되는 시스템에서 인터프리터, JIT 컴파일 등의 기계어 번역을 통해 중간 언어를 미리 목표 시스템에 맞는 기계어로 번역하는 것을 지칭한다.
즉, AOT를 쓰면 실제 자바코드를 모르게 되면서 JIT이 실행하는 최적화를 제대로 할 수 없을 수도 있다. (왜냐하면 프로세서의 특정 기능을 사용할 기회를 놓친다.) 하지만 AOT 실행을 하면 JIT 보다 시작시간이 훨씬 빠르다. [1]
핫스팟은 이외에도 많은 최적화를 한다. 시동될 때, CPU 타입을 정확히 감지해 가능하면 특정 프로세서의 기능에 맞게 최적화를 적용한다.
핫스팟 특유의 정교한 접근 방식 덕분에 많은 혜택을 누리지만, 제로-오버헤드 추상화를 포기한 탓에 고성능 자바 애플리케이션 개발을 할 때 소위 '상식적인' 추론으로 동작하는 방식을 넘겨짚지 말자.
3.3.2 제로 오버헤드란?
C++ 창시자 비야네 스트롭스트룹의 말을 인용하자
C++ 코드는 제로-오버헤드 원칙을 준수합니다. 사용하지 않는 것에는 대가를 치르지 않습니다. 즉, 여러분이 사용하는 코드보다 더 나은 코드를 건네줄 수는 없습니다.
3.4 JVM 메모리 관리
자바를 독보적으로 만들었던 특징은 바로 자동 메모리 관리(automatic memory management)기능이다.
자바는 가비지수집(Carbage Collection)이라는 프로세스로 힙 메모리를 자동 관리한다. 즉, JVM이 더 많은 메모리를 할당해야할 때, 불필요한 메모리를 회수하거나 재사용하는 불확정적(nondeterministic) 프로세스다.
3.5 스레딩과 자바 메모리 모델(JMM)
자바는 1.0부터 멀티스레드를 지원했다.
Thread t = new Thread(() -> { System.out.pinrlnt("Hello World!");});
t.start(); // OS 스레드가 생성됨.
멀티스레드 기반이기에 자바 프로그램은 한층 더 복잡해지고, 성능 분석도 하기 힘들어졌다. 주류 JVM 구현체에서 자바 애플리케이션 스레드는 각각 정확히 하나의 전용 OS스레드에 대응된다. 공유 스레드풀을 이용해 전체 자바 애플리케이션 스레드를 실행하는 방법도 있지만(green threads), 쓸데없이 복잡도만 가중되고 성능은 높지않다.
1990후반부터 자바 멀티스레드 방식은 다음 세 가지 설계 원칙에 기반한다.
- 자바 프로세스의 모든 스레드는 가비지가 수집되는 하나의 공용 힙을 가진다.
- 한 스레드가 생성한 객체는 그 객체를 참조하는 다른 스레드가 엑세스할 수 있다.
- 기본적으로 객체는 변경 가능하다(mutable). 즉,
final키워드를 쓰지 않는 이상 바뀔 수 있다.
3.6 JVM 모니터링과 툴링
3.6.1 JMX(Java Management Extensions)
JVM 위에서 동작하는 애플리케이션을 제어 및 모니터링하는 범용 툴.
3.6.2 자바 에이전트(Java agent)
java.lang.instrument 인터페이스로 메서드 바이트코드를 조작한다.
JVM 시작 플래그를 추가하면 된다. ( -javaagent:<에이전트 JAR 파일 경로>=<옵션> )
에이전트 JAR 파일에서 manifest(manifest.mf)는 필수다. 또 Premain-Class 속성에 에이전트 클래스명을 반드시 지정해야 한다.
이 클래스는 public static premain() 메서드를 구현하고 있다. premain() 은 자바 에이전트의 등록 후크(registration hook) 역할을 한다.
자바의 instrument는 JVM이 로드한 바이트코드를 조작하는 기술로 main 이 실행되기 전에 premain 에게 바이트코드를 넘겨서 조작할 수 있도록 하는 것이다.
3.6.3 VisualVM
http://visualvm.java.net/ 에서 파일을 내려받아서 쓸 수 있다.
실시간 모니터링할 수 있다. 자세한 내용은 나중에 사용할 때 보도록.
4 하드웨어와 운영체제
4.1 하드웨어 메모리 모델
"어떻게 하면 서로 다른 CPU가 일관되게 동일한 메모리 주소를 엑세스 할 수 있을까?" 는 멀티코어 시스템에서 메모리에 관한 근본적인 물음이다.
JIT 컴파일러인 javac와 CPU는 코드 실행순서를 바꿀 수 있다. (물론 순서가 바껴도 상관없을 때)
myInt = otherInt; intChanged = true;
위 두 코드는 순서를 바꿀 수 있다. 그러나, 다른 스레드입장에서 실행 순서가 바뀌는 intChanged는 true를 읽겠지만, myInt는 이전 값을 볼 수도 있다.
JMM은 프로세서 타입별로 메모리 엑세스 일관성을 고려하여 명시적으로 weak model 을 설계했다. (weak memory model)
하여 멀티스레드 코드가 제대로 작동하려면 락과 volatile을 정확히 알고 써야한다.
4.2 운영체제
4.2.1 스케줄러
process scheduler 는 CPU엑세스를 통제한다. 이때 실행 큐(run queue)를 이용한다.(차례를 기다리는 스레드|프로세스의 대기장소)
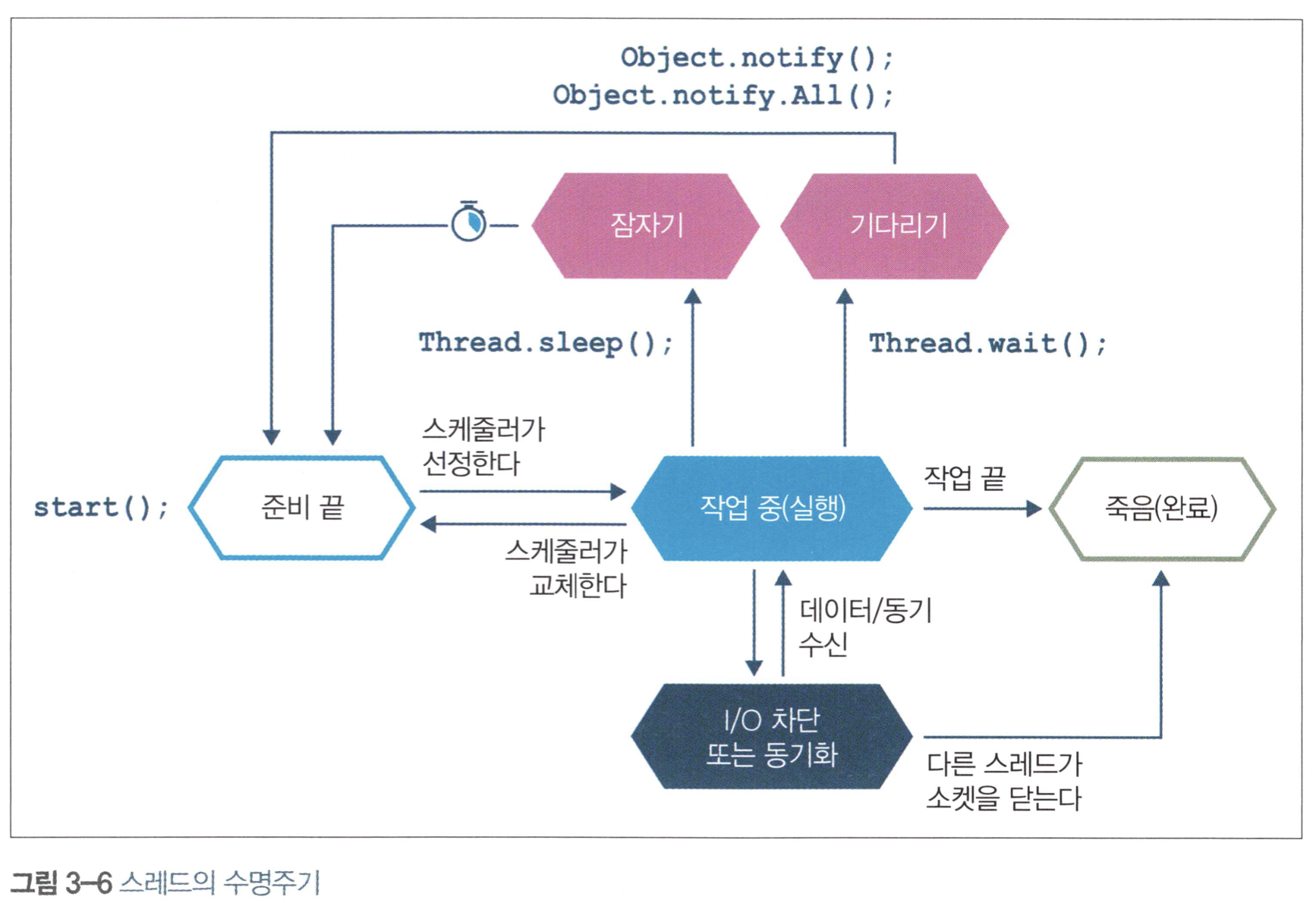
Figure 2: Thread Lifecycle
그림 속 OS스케줄러는 스레드를 시스템 단일 코어로 보낸다. 스케줄러는 할당 시간(구형OS는 보통 10~100밀리초, OS에 따라 다른 듯) 끝 무렵에 실행 큐로 스레드를 되돌려서 큐의 맨 앞으로 가 다시 실행될 때까지 대기시킨다.
스레드가 자신에게 할당받은 시간 자발적으로 포기하려면 sleep() 메서드로 잠들시간을 명시하거나 wait() 으로 대기 조건을 명시한다.
스레드는 I/O 또는 소프트웨어 락에 걸려 블로킹 될 수도 있다.
OS는 특성상 CPU에서 코드가 실행되지 않는 시간을 유발한다. (간과하기 쉬운 OS특징) 자신의 할당 시간을 다 쓴 프로세스는 실행 큐 맨 앞으로 갈 때까지 CPU로 복귀하지 않는다. CPU가 아껴 써야 할 리소스인데, 실행되는 시간보다 기다리는 시간이 더 많다는 뜻이다. (이것은 실행되고 있는 다른 시스템의 영향을 받기도 한다.)
스케줄러의 움직임은 OS가 스케줄링 과정에서 발생시킨 오버헤드를 관측하는 것으로 쉽게 알 수 있다. 아래 코드를 보다.
// 1밀리초씩 총 1,000회 스레드를 재운다.
// 스레드는 한번 잠들 때마다 실행 큐 맨 뒤로 가고 새로 시간을 할당받을 때까지 기다리므로
// 이 코드의 총 실행 시간을 보면 여느 프로세스에서 스케줄링 오버헤드가 얼마나 될지 짐작할 수 있다.
long start = System.currentTimeMillis();
for (int i = 0; i < 1_000; i++) {
Thread.sleep(1);
}
long end = System.currentTimeMillis();
System.out.println("Millis elapsed: " + (end - start) / 4000.0);
(즉, 1000밀리초가 재우는데 쓰이는 시간일 것이다. 그 외 시간을 오버헤드로 대강 보면 된다는 뜻인듯.)
이것은 OS마다 코드 실행 결과는 천차만별이다. 유닉스는 대략 10%~20%가 오버헤드다. 윈도우 XP는 180%정도였다. 즉, 1밀리초 1000번 잠드는데 1초가 걸리는데 2.8초가 걸리는 것이다.
4.2.2 시간 문제
POSIX(portable operating system interface) 같은 업계 포준이 있어도 OS마다 다르게 작동한다.
os:javaTimeMillis() 함수가 그 예이다. 이 함수는 OS에 의존하므로 네이티브로 구현되어 있다.
다음은 BSE 구현체이다.
jlong os::javaTimeMillis() {
timeval time;
int status = gettimeofday(&time, NULL);
assert(status != -1, "bsd error");
return jlong(time.tv_sec) * 1000 + jlong(time.tv_usec / 1000);
}
마이크로소프트 구현체는 완전히 다르다.
jlong os::javaTimeMillis() {
if (UseFakeTimers) {
return fake_time++;
} else {
FiLETIME wt;
GetSystemTimeAsFileTime(&wt);
return window_to_java_time(wt);
}
}
4.2.3 컨텍스트 교환
OS스케줄러가 현재 실행 중인 스레드/태스크를 없애고 대기 중안 다른 스레드/태스크로 대체하는 프로세스이다.
크게 두 가지 방식으로 분류된다.
- 유저스레드 사이 컨텍스트 교환
- 유저 모드에서 커널 모드로 바뀌면서 일어나는 교환(특히 비쌈)
유저스레드가 타임 슬라이스(preemption, OS가 멀티태스킹을 위해 프로세스의 동의 없이 임의로 인터럽트를 걸고 나중에 프로세스를 재개하는 것) 도중 커널모드로 바꿔서 어떤 기능을 실행해야 할 때가 있다. 하지만 (유저 공간에 있는 코드가 엑세스하는) 메모리 영역은 커널 코드와 공유되는 부분이 거의 없다. 그래서 모드가 바뀌면 명령어와 다른 캐시를 강제로 비워야 한다.
커널모드로 교환되면 TLB(변환 색인 버퍼는 가상 메모리 주소를 물리적인 주소로 변환하는 속도를 높이기 위해 사용되는 캐시로, 약칭은 TLB이다) 외 다른 캐시도 무효화된다. 이들은 시스템 콜 반환 시 다시 채워야 하므로 커널 모드 변환의 여파는 유저 공간으로 다시 제어권이 (유저에게로) 넘어간 후에도 당분간 이어진다.
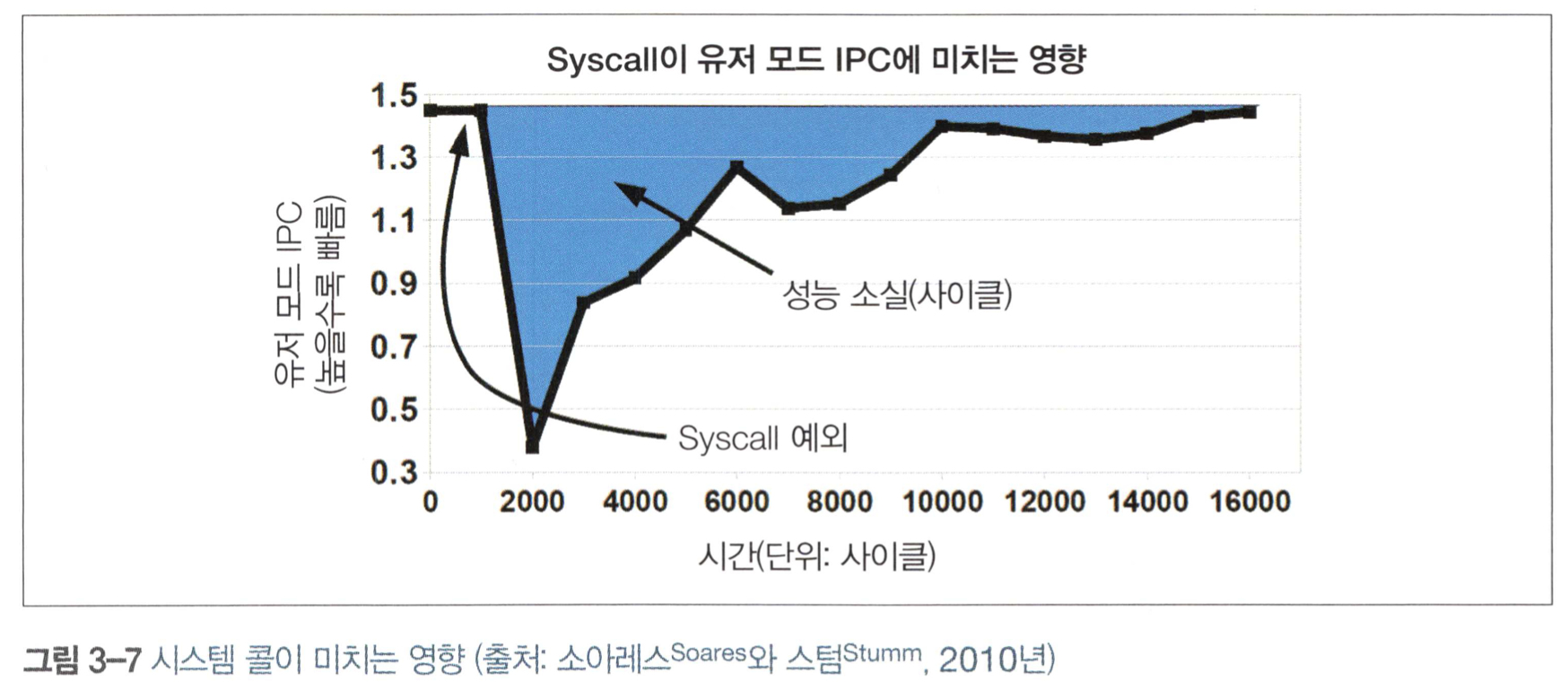
Figure 3: System Call
리눅스는 이를 만회하려고 가상 동적 공유 객체(virtual Dynamically Shared Object, vDSO)라는 장치를 제공함.
4.3 기본 감지 전략
애플리케이션이 잘 돌아간다는 건 CPU 사용량, 메모리, 네트워크, I/O 대역폭 등 시스템 리소스를 효율적으로 잘 이용한다는 뜻이다.
4.3.1 CPU 사용율
CPU의 효율적 사용은 성능 향상의 지름길이다. 부하가 집중되는 도중에는 사용률이 가능한 한 100%에 가까워야 한다. (100%가 되지 않고 부하가 밀리면, I/O 같은 다른 곳에 병목이 있는 것이니 리소스를 효율적으로 쓰고 있는 것이 아니다)
우선 vmstat, iostat를 쓸 줄 알아야 한다.
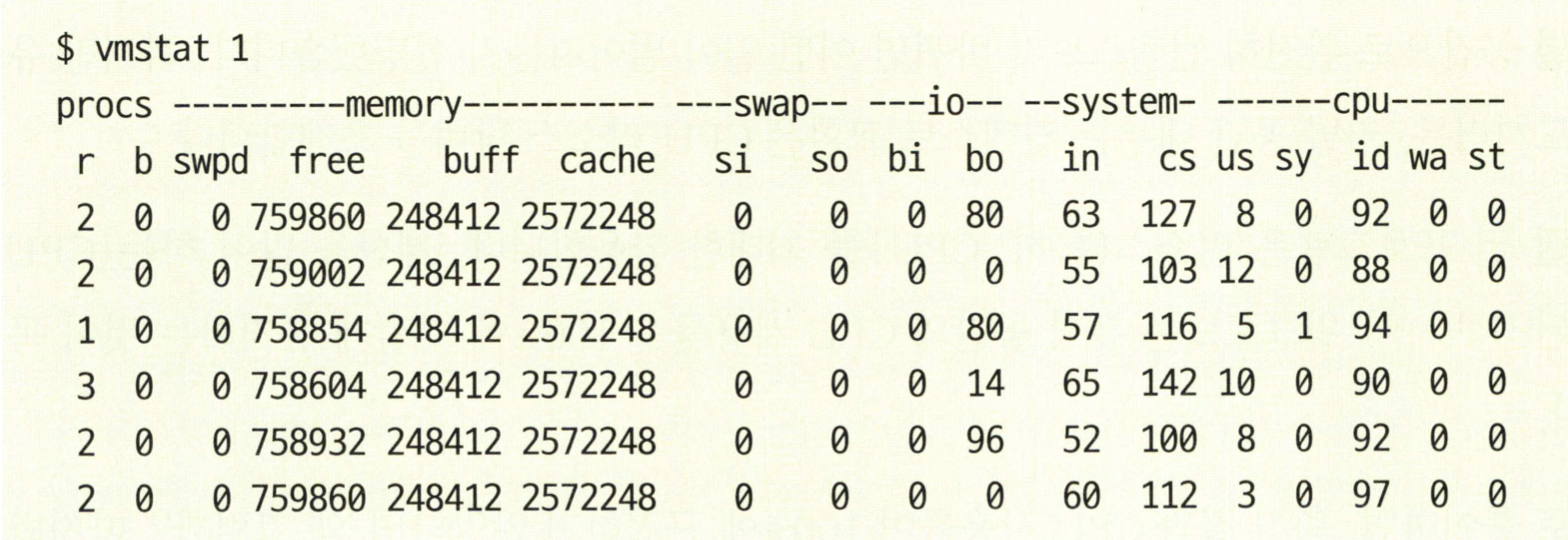
Figure 4: vmstat
vmstst 1 는 1초마다 찍어서 결과를 출력한다. 출력내용을 보자
- procs 섹션 : 실행가능한(r) 프로세스, 블로킹된(b) 프로세스 개수를 나타냄.
- memory 섹션 : 스왑메모리(swpd), 미사용 메모리(free), 버퍼로 사용된 메모리(buff), 캐시로 사용한 메모리(cache)가 나열됨.
- swap 섹션 : 디스크로 교체되어 들어간(스왑-인) 메모리(si), 디스크에서 교체되어 빠져나온(스왓-아웃) 메모리(so) 정보. (최신 서버급 머신은 스왑이 많이 일어나지 않음)
- io 섹션 : 블록-인(bi), 블록-아웃(bo) 개수는 각각 블록(I/O)장치에서 받은 512바이트 블록, 블록 장치로 보내 512바이트 블록 개수.
- system 섹션 : 인터럽트(in), 초당 컨텍스트 교환(cs) 횟수.
- cpu 섹션 : CPU와 직접 연관된 지표들. 유저 시간(us), 커널 시간(sy), 유휴 시간(id), 대기 시간(wa), 도둑맞은 시간(st, 가상머신에 할애된 시간)
vmstat로 측정결과 부하가 있을 때, CPU가 100%에 근접하지 않으면 고민을 해야 한다. 락 때문인가, 컨텍스트 교환 때문인가, I/O경합이 일어나 블로킹이 일어나는 것은 아닐까? 유저 공간에서 CPU사용률이 100%가 안되었는데, 컨텍스트 교환 비율이 높으면 I/O블로킹이 일어나거나, 스레드 락 경합(thread lock contention) 이 벌어졌을 공산이 크다.
하지만 스레드락 경합을 실시간 감지하려면 비주얼툴이 필요하다.(VisualVM 같은 거)
4.3.2 가비지 수집
핫스팟 JVM은 시작시 메모리를 유저 공간에 할당/관리한다. 그래서 메모리 할당을 위해 시스템콜을 할 필요가 없다.
따라서 어떤 시스템에서 CPU 사용률이 아주 높게 나온다면, GC는 대부분의 시간을 소비하는 주범이 아니다. GC 자체는 유저 공간의 CPU 사이클을 소비하되 커널 공간의 사용률에는 영향을 미치지 않는다.
반면, 어떤 JVM 프로세스가 유저 공간에서 CPU를 100% 가깝게 사용하면 GC를 의심하자. 이것이 GC이 범인인지 유저코드가 범인인지 알아야 한다. JVM에서 유저 공간의 CPU 사용률이 높은 건 거의 대부분 GC 서브시스템 탓이다. GC 로그를 확인하고 새 항목이 추가되는 빈도를 확인하자.
JVM에서 GC 로깅은 거의 공짜나 다름없다. GC 로깅은 분석용 데이터의 원천으로서도 가치가 높기 때문에 JVM 프로세스는 예외 없이, 특이 운영 환경에는 GC로그를 꼭 남겨야 한다.
4.3.3 입출력
파일I/O는 예로부터 전체 시스템 성능에 암적인 존재였다. I/O는 다른 OS파트처럼 분명하게 추상화되어 있지 않다.
예로, 메모리 분야는 '가상 메모리'라는 격리장치가 있지만, I/O는 개발자가 추상화할 장치는 없다. 자바 프로그램은 대부분 단순한 I/O만 처리하며, I/O서브시스템을 심하게 가동시키는 애플리케이션 클래스도 비교적 적은 편이라고 한다.
4.3.4 기계공감
자동차 경주 선수가 되려고 엔지니어가 될 필요는 없지만 기계를 공감할 줄은 알아야 한다. - 재키 스튜어트 -
기계 공감은 자바 개발자가 무시하기 쉬운 관심사이다. JVM이 하드웨어를 추상화했는데 굳이 알 필요는 없다. 하지만 고성능, 저지연이 필수인 분야에서 자바/JVM을 효과적으로 사용하려면 JVM이란 무엇이고, 하드웨어와는 어떻게 상호작용하는지 이해해야 한다.
4.4 JVM과 운영체제
JVM은 자바 코드에 공용 인터페이스(common interface)를 제공하여 OS독립적인 portable 실행 환경을 제공한다. 하지만 스레드 스케줄링은 기본적인 서비스도 하부 OS에 반드시 엑세스 해야 한다.
이런 기능은 native 키워드를 붙인 네이티브 메서드로 구현한다. (C|C++)언어로 작성하여 자바 메서드 처럼 접근할 수 있다.
이 작업을 대행하는 공통 인터페이스를 JNI(Java Native Interface)라고 한다.
예로, 자바 Object의 native 메서드를 보자.
public final native Class<?> getClass(); public native int hashCode(); protected native Object clone() throws CloneNotSupportedException; public final native void notify(); public final native void notifyAll(); public final native void wait(long timeout) throws InterruptedException;
아래 네이티브 코드를 호출하는 방식을 보여준다.
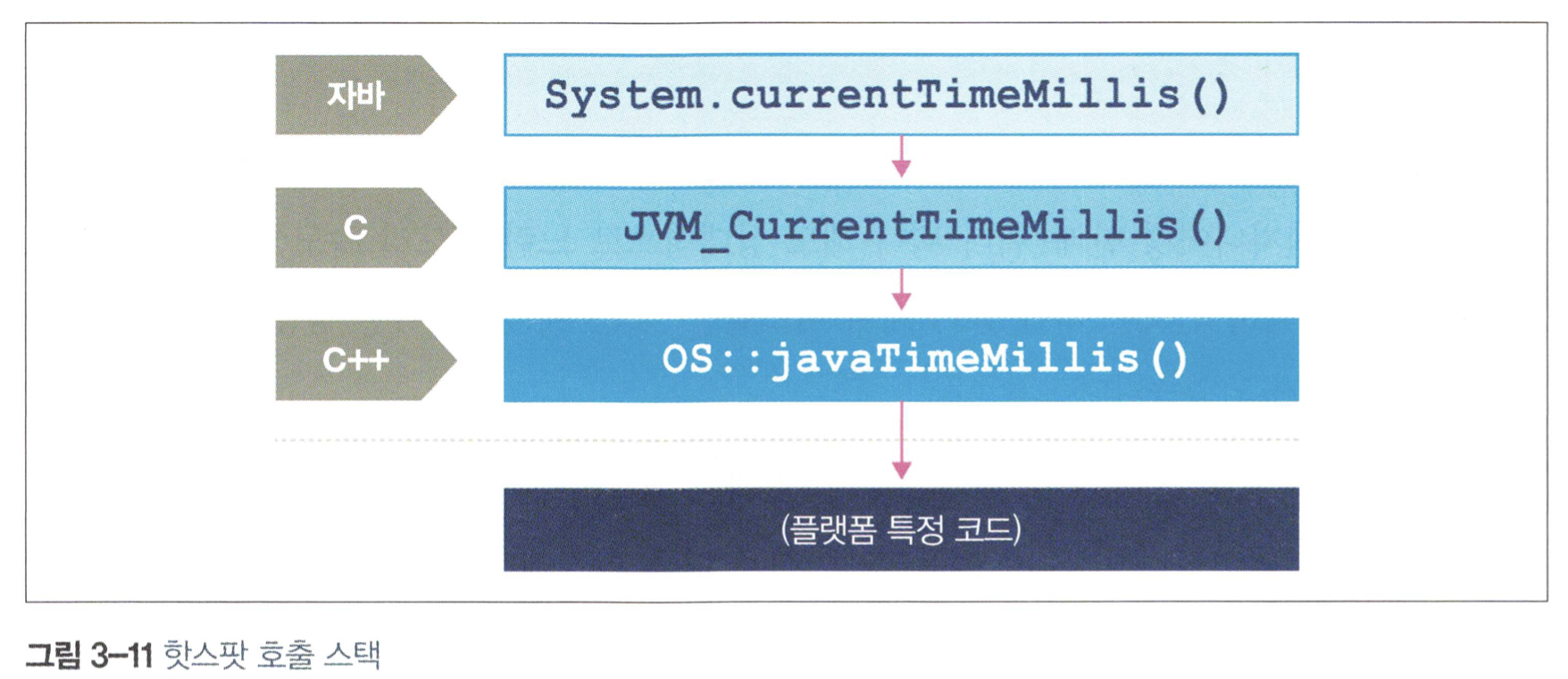
Figure 5: jni
OpenJDK 코드베이스를 보면 OS별로 서브디렉터리 어딘가에 소스코드가 있다.
5 성능 테스트 패턴 및 안티패턴
5.1 성능 테스트 유형
- 지연 테스트(Latency Test) : 종단 트랜잭션에 걸리는 시간은?
- 처리율 테스트(Throughput Test) : 현재 시스템이 처리 가능한 동시 트랜잭션 개수는?
- 부하 테스트(Load Test) : 특정 부하를 시스템이 감당할 수 있는가?
- 스트레스 테스트(Stress Test) : 이 시스템의 한계점(breaking point)는 어디까지인가?
- 내구성 테스트(Endurance Test) : 시스템을 장시간 실행하면 성능 이상 증상이 나타나는가?
- 용량 계획 테스트(Capacity planning Test) : 리소스를 추가한 만큼 시스템이 확장되는가?
- 저하 테스트(Degration Test) : 시스템이 부분적으로 실패하면 어떤 일이 벌어지는가? (어떻게 복원되는지? resilience, failover,,,)
5.2 성능 안티패턴 개요
성능 튜닝의 안티패턴을 나열한다.
- 지루함
개발자의 지루함은 프로젝트에 여러가지 해악을 끼칠 수 있다.
지금까지 알려지지 않은 기술로 컴포넌트를 제작하거나, 잘 맞지 않는 유스케이스에 억지로 기술을 욱여넣는 여러가지 방법으로 지루함을 표출한다.
- 이력서 부풀리기
이력서 과대포장할 구실을 찾는 개발자가 있다.
- 또래 압박(peer pressure)
팀원이 기술을 결정할 때 관심사를 분명히 밝히지 않고, 서로 충분한 논의 없이 진행하면 쓰디쓴 결과를 맛보기 쉽다. 가령, 특정 주제를 자신이 잘 모른다는 사실을 두려워하는 개발자가 있다.
경쟁심이 불타오르는 팀 속에서 개발이 광속으로 진행되는 듯 보이고자 제대로 사정을 따져보지도 않고 섣불리 중요한 결정을 내리는 것도 또래 압박의 아주 고약한 형태이다.
- 이해 부족
지금 사용하는 툴의 기능도 온전히 알지 못하는데 무턱대고 새로운 툴로 문제를 해결하려는 개발자가 있다. 새로 나온 기술이 좋다는 소문이 퍼지면 사람 마음이란게 기울어지게 마련이다. 하지만 기술 복잡도를 높이는 것보다 현재 툴로도 할 수 있는 것 사이의 균현을 잘 맞추어야 한다.
예를 들어, 하이버네이트(Hibernate)는 도메인 객체 <-> DB 객체 변환을 단순화하는 절호의 방법처럼 보인다. 이 기술을 겉핥기 식으로 아는 개발자는 다른 프로젝트에서 다 쓰더라~ 하는 경험담을 말하면서 이 기술이 적합하다고 쉽게 단정한다.
이처럼 이해가 부족한 상태에서 하이버네이트를 너무 복잡하게 사용하면 운영 단계에서 회복 불가 단계를 맞이할 수 있다. 필자의 수강생 중에 하이버네이트를 열심히 연구했지만, 결국 걷어내느라 주말을 반납했다고 한다.
- 오해와 있지도 않은 문제가
문제 자체를 이해하지 못한 채 오로지 기술을 이용해서 문제를 해결하려는 개발자도 있다. 설령 성공해도, 성능 수치 측정을 안했다면 어떻게 성공을 장담할까요? 성능 지표를 수집/분석해야만 비로소 문제의 본질을 정확히 이해할 수 있습니다.
무언가 불분명하면 먼저 사실에 근거한 증거를 수집하고 프로토타입을 만들어 조사합니다. 최신 기술이 아무리 좋아보여도 프로토타입을 만들어보니 기대에 미치지 못할 수 있습니다.
5.3 성능 안티패턴 카탈로그
5.3.1 화려함에 사로잡히다
최신의 멋진 기술이 접목된 컴포넌트를 찾아 튜닝 타깃으로 정한다. 레거시 코드를 파헤지는 것보다 신기술의 작동 원리는 연구하는게 더 재밌기 때문이다.
흔히 하는 말
- 처음이라 말썽이 많군. 뭐가 문제인지 원인을 밝혀야 해.
현실
- 애플리케이션을 측정하고 튜닝하지 않는다.
- 신기술에 대해 제대로 모르기 때문에 문제가 커질 수 있다.
- 신기술에 대한 예제는 보통 작은 규모의 전형적인 데이터셋을 다룬다. 기업 규모로 확장하는데 필요한 베스트 프랙티스는 일언반구도 없다.
이런 안티패턴은 신생팀이나 숙련도가 떨어지는 팀에서 흔하다. 자신의 능력을 증명하려는 욕구, 레거시 시스템이라고 간주한 것에 매이지 않으려는 마음으로 오로지 최신 '뜨고 있는' 기술을 숭배한다. 그런데 마침 그들이 새 직장에서 고액의 연봉을 받기 딱 좋은 그런 종류의 기술인 경우가 많다.
처방
- 측정해보고 진짜 성능 병목을 찾아라
- 새 컴포넌트는 전후로 충분한 로그를 남겨라
- 베스트 프랙티스 및 단순화한 데모를 참조하라
- 팀원들이 새 기술을 이해하도록 독려하고 팀 차원의 베스트 프랙티스 수준을 정하세요.
5.3.2 단순함에 사로잡히다
애플리케이션을 프로파일링해서 객관적으로 아픈부위를 들추지 않고 제일 간단한 부분만 파고든다.
흔히 하는 말
- 우리가 알고 있는 부분부터 파봅시다.
- 그건 존이 개발했는데 지금 휴가 갔어요. 기다립시다.
현실
- 원개발자는 그 시스템파트(혹은 해당파트만)어떻게 튜닝해야할지 안다.
- 다양한 시스템 컴포넌트에 대한 지식 공유를 하지 않고, 짝 프로그래밍을 안 한 결과, 독보적인 전문가만 양산된다.
이것은 새로운 기술이 접목된 시스템을 맡으려하지 않는 것이다. '화려함에 사로잡힌' 개발자들이 욕망이 공격적으로 드러나며, '단순함에 사로잡힌'개발자들은 긁어 부스럼 만들지도 모르는 신기술에 관여하느니 익숙한 것만 갖고 놀겠다는 방어 태세이다.
처방
- 성능을 측정하고 진짜 성능 병목을 찾아라
- 본인이 익숙하지 않은 컴포넌트에 문제가 생기면 전문가에게 도움을 청하라
- 개발자가 전체 시스템 컴포넌트를 고루 이해하도록 독려하라
5.3.3 성능 튜닝 도사
할리우드 영화에 나오는 '고독한 천재' 해커 모습에 빠져서 그런 이미지의 전문가를 수소문하여 채용한다. 그리고 명성에 맞게 사내 모든 성능 이슈를 바로잡아달라고 특명을 내린다.
흔히 하는 말
- 나도 문제가 XXX라는 건 알고 있어
현실
- 결국 하는 일이라곤 드레스코드(복장규정)에 도전하는 일이 고작이다.
물론, 특정 기술에 정통한 전문가는 있겠지만, 모든 성능 이슈를 처음부터 다 간파한, 고독한 천재의 존재는 터무니 없다. 성능 전문가는 대부분 성능 지표를 측정하고 그 결괏값을 바탕으로 문제를 해결하는 사람이다.
특정 이슈를 해결한 방법이나 자기가 알고 있는 걸 절대로 남과 공유 안하려는, 초인을 지향하는 팀원은 매우 반생산적(counterproductive)이다.
5.3.4 민간 튜닝
문제 해결방법을 찾아 헤매다가 한 팀원의 웹사이트에서 '마법'의 설정 매개변수를 발견한다. 인터넷에 글을 쓴 사람이 호언장담해서 테스트도 하지 않고 바로 매개변수를 운영에 적용하는데…
흔히 하는 말
- 스택 오버플로에 이런 멋진 팁이 있더라고. 이제 다 끝났어.
무엇인지 잘 모르고 사용하면 어떤 영향을 미칠지 모른다. 성능팁은 유통 기한이 짧다. 그리고 자바는 계속 진화하는 플랫폼이기에 어느 버전에서 해결이 되던 것이 다른 버전에서는 안 먹힐 수 있다.
5.3.5 안되면 조상 탓
정작 이슈와 상관없는 특정 컴포넌트를 문제 삼는다.
DB테이블에 락이 걸렸고, 에러를 내뿜었지만 락은 풀리지 않아 애플리케이션이 멎어버렸다. 사람들은 약속이나 한 듯 데이터 엑세스 계층에 사용한 하이버네이트가 원인이라고 비난했지만 타임아웃 예외를 붙잡은 catch 블록에 DB커넥션을 정리하는 코드를 안 넣은 것이 진짜 원인이었다. 개발자가 하이버네이트 비난을 멈추고 정말 버그를 일으킨 자신들의 코드를 직시하기까지 꼬박 하루가 걸렸다.
흔히 하는말
- JMS, 하이버네이트, 그 머시기 라이브러리가 항상 문제라니깐!
현실
- 분석도 안해보고 결정을 내림
- 평소 의심했던 범인을 유일한 용의자로 지목함
- 진짜 원인을 밝히려면 숲을 봐야 하는데 팀원들은 그럴 마음이 없다
처방
- 성급한 결론을 내리고픈 욕망을 버리자
- 정상적으로 분석하자
- 분석 결과를(문제 원인 구체화를 위해) 모든 이해 관계자와 의논하자
5.4 인지 편향과 성능 테스트
인지 편향(cognitive bias)은 인간의 두뇌가 부정확한 결론을 내리게 이끄는 심리 작용이다. 편향을 보이는 사람이 대게 자신이 그런 줄도 모르고 스스로는 아주 이성적이라고 믿는 게 더 큰 문제이다.
5.4.1 환원주의 (reductionist thinking)
시스템을 아주 작은 조각으로 나눠서 조각들을 이해하면 전체 시스템을 다 이해할 수 있다는 분석주의적 사고방식이다. 각 파트를 이해하면 그릇된 가정을 내릴 가능성도 작을 거라는 편향된 논리.
복잡한 시스템은 그렇지 않다. 소프트웨어는 거의 항상 예기치 않은 순간에 돌변한다. 단순히 파트들을 합한 것보다 시스템을 전체로 바라봐야 문제의 원인을 찾을 수 있다.
5.4.2 확증 편향(Confirmation bias)
확증 편향은 일반적으로 내가 원하는 바대로 정보를 수용하고 판단한다는 뜻이다. 테스트 몇가지를 하고 만족할 만한 결과가 나왔다고 검증되지 않은 가설을 믿는 것은 위험하다.
5.4.3 전운의 그림자(행동 편향, Action bias)
어떤 불분명한 상황이 나타날 때, 나쁜 결과가 나오더라도 가만 있는 것보다 행동하는 것이 낫다는 믿음이다. 예를들어
- 영향도를 분석하지 않고, 다른 사람에게 연락하지 않고 시스템 인프라를 변경한다.
- 시스템이 의존하는 라이브러리를 변경한다.
- 연중 가장 업무가 빠듯한 날을 처음보는 버그나 경합 조건이 발생한다.
5.4.4 위험 편향
인간의 본성은 위험을 피하고 변화를 거부한다. 누구나 예전에 뭔가 바꿨더니 잘못됐던 경험을 한 두가지 갖고 있어서 가급적 위험을 감수하지 않으려고 한다.
5.4.5 엘스버그 역설(Ellsberg's Paradox)
엘스버그 역설은 인간이 확률을 이해하는데 얼마나 서투른지 잘 보여주는 사례이다.
예를 보자. 통 안에 90개의 공이 있다. 30개는 파란 공, 나머지는 빨간 공 아니면 녹생 공이라고 하자. 빨간 공, 녹색 공의 비율은 모른다. 통은 하나밖에 없고, 전체 공의 개수는 정해져 있으니 확률은 일정하다.
이 역설의 첫 단계는 어떤 내기를 할지 선택하는 것이다. 참가자는 다음 내기 중 하나를 선택한다.
A. 통에서 꺼낸 공이 파란 공이면 $100을 받는다. B. 통에서 꺼낸 공이 빨간 공이면 $100을 받는다.
대부분 사람은 A를 선택한다. 이길 확률이 정확히 1/3 이니까. 그러나 꺼낸공을 다시 넣고 섞은 다음에 다음과 같이 두번째 내기를 한다면 놀라운 일이 벌어진다.
C. 통에서 꺼낸 공이 파란 공 또는 녹색 공이면 $100을 받는다. D. 통에서 꺼낸 공이 빨간 공 또는 녹색 공이면 $100을 받는다.
이때 사람은 대부분 이길 확률(2/3)이 뻔한 D를 고른다. 하지만 역설적으로 A/D는 비이성적인 선택이다. A를 선택한 것은 빨간 공과 녹색 공이 어떤 분포일 거라는 의사(즉, 녹색 공이 빨간 공보다 많을 거라는)를 암묵적으로 나타낸 것이다. 따라서 기왕 A를 선택했다면 논리적으로 D보다 이길 확률이 높은 C를 잇따라 선택하는 것이 더 우세한 전략이다.
6 마이크로 벤치마킹과 통계
6.1 자바 성능 측정 기초
100,000개 숫자를 정렬하는 벤치마크 코드를 예로 보자.
public class ClassicSort {
private static final int N = 1_000;
private static final int I = 150_000;
private static final List<Integer> testData = new ArrayList<>();
public static void main(String[] args) {
Random randomGenerator = new Random();
for (int i = 0; i < N; i++) {
testData.add(randomGenerator.nextInt(Integer.MAX_VALUE));
}
System.out.println("정렬 알고리즘 테스트");
double startTime = System.nanoTime();
for (int i = 0; i < I; i++) {
List<Integer> copy = new ArrayList<>(testData);
Collections.sort(copy);
}
double endTime = System.nanoTime();
double timePerOperation = ((endTime - startTime) / (1_000_000_000L * I));
System.out.println("결과: " + (1 / timePerOperation) + " op/s");
}
}
I번 루프가 끝난 후 소요 시간을 초 단위로 나누면 작업당 소요시간(timePerOperation)이 계산된다.
이 벤치마크의 문제는 JVM 웜업을 고려하지 않았다는 점이다. 운영에 올린 애플리케이션은 몇시간 혹은 며칠이 걸리 수는 있지만, JIT 컴파일러가 JVM에 내장된 덕분에 인터프리티드 바이트코드는 고도로 최적화한 기계어로 변환된다. JIT 컴파일러는 메소드를 몇 번 실행해본다음 곧바로 임무를 개시한다.
따라서 이 테스트만으로는 운영시스템에서 어떻게 작동하는지 확실히는 모른다. 정말 그런지 보자.
java -Xms2048m -Xmx2048m -XX:+PrintCompilation ClassicSort
PrintCompilation 은 메서드를 컴파일 할 때마다 로깅하라는 지령이다. 이걸 쓰면 컴파일 이벤트가 여러번 발생하는 것을 볼 수 있다.
하지만 운영 시스템에서는 웜업 이후에는 수행되지 않을 수도 있는 것들이다. JIT 컴파일러는 이런 호출 계층(call hierachy)를 최적화한다.

Figure 6: PrintCompilation1
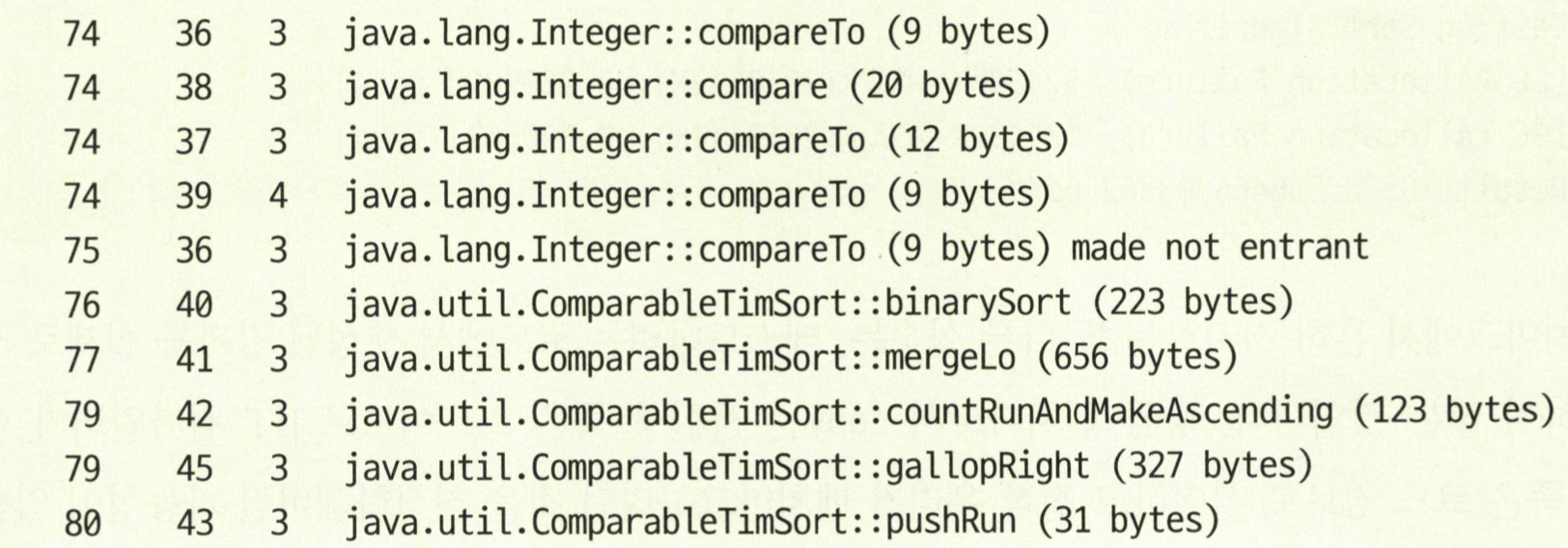
Figure 7: PrintCompilation2
가비지 수집여부도 고려하자. GC가 일어나지 않게 하는 것도 좋은 방법이지만, GC는 원래 nondeterministic(불확정적)이기 때문에 어쩔 수 없다. 아래 플래그로 GC가 작동하는 모습을 볼 수 있다.
java -Xms2048m -Xmx2048m -verbose:gc ClassicSort
다음처럼 GC로그 엔트리가 보인다.

Figure 8: gc flag
벤치마크에서 저지르는 또 다른 실수는, 테스트 하려는 코드를 실제로는 사용하지 않는 경우다.
위 코드에서 copy 는 사실상 복사하고 쓰지 않기 때문에 JIT 컴파일러가 테스트해야 하는 코드임에도
제거할 수 있다. (copy가 병목인지 알려고 했다면 실패할 것이다)
이 외에도 여러 이유가 있는데 대부분 이유는 전체를 보지 못해서라고 함.
해결방법
- 시스템 전체를 벤치마크한다.
- 연결된 저수준 결과를 의미있게 벤치마크하기 위해 공통 프레임워크를 이용해 처리한다. JMH가 그런 툴이다.
6.2 JMH 소개
6.2.1 될 수 있으면 마이크로벤치마크하지 말지어다. (실화)
개선한 애플리케이션에 성능 문제가 곧잘 터져서 코드 일부를 위한 소규모 벤치마크를 작성하는데 시간을 보내는 개발자가 있었다. 필자는 개발자에게 이런 '건초 더미에서 바늘 찾는'방식은 아닌 것 같다고 말하며 접근을 달리했다.
원인은 코드가 아니라 새로 들여온 인프라 라이브러리가 화근이었다. 개발자는 큰 그림을 못 보고 자기 코드가 성능을 떨어뜨렸을 거라는 강박에 사로잡힌다.
6.2.2 휴리스틱: 마이크로벤치마킹은 언제 하나?
2장에서 언급했듯이, 자바 플랫폼은 천성이 동적이고 가비지수집 및 공격적인 JIT 최적화 같은 특성으로 성능을 직접 가늠하기 어렵다.
해서 작은 자바 코드보다 자바 애플리케이션 전체를 대상으로 성능 분석을 하는 편이 거의 항상 더 수월하다.
하지만 어쩔 수 없는 경우는 무엇인가?
- 사용 범위가 넓은 범용 라이브러리 코드를 개발한다
- OpenJDK 또는 다른 자바 플랫폼 구현체를 개발한다
- 지연에 극도로 민감한 코드를 개발한다 (예: 저지연거래)
6.2.3 JMH 프레임워크를
앞서 거론한 이슈를 해소하고자 개발된 프레임워크이다.
JMH는 자바를 비롯해 JVM을 타깃으로 하는 언어로 작서된 나노/마이크로/밀리/매크로 벤치마크를 제작, 실행, 분석하는 자바도구이다.
- OpenJDK
JMH는 JVM을 빌드한 사람들이 직접 만든 프레임워크다.
벤치마크 프레임워크는 컴파일 타임에 벤치마크 내용을 알 수 없으므로 동적이어야 한다. 리플렉션을 쓰기도 하지만, 벤치마크 실행 경로에 복잡한 JVM 서브시스템이 끼어드는 것이다. 그래서 JMH는 벤치마크 코드에 애너테이션을 붙여 자바 소스를 추가 생성하는 식으로 작동한다. (애너테이션 프로세싱을 말하는 듯하다)
6.2.4 벤치마크 실행
JMH 프로젝트를 새로 만들다.

Figure 9: JMH Proejct
필요한 아티팩트를 모두 내려받으면 코드를 짜 넣을 벤치마크 스텁이 생성된다.
이 프레임워크가 여러 설정 태스크를 마친 후 실행시킬 벤치마크 메서드에는 @Benchmark 를 붙인다.
public MyBenchmark {
@Benchmark
public void testMethod() {
// code stub
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(SortBenchmark.class.getSimpleName())
.wramupIterations(100)
.measurementIterations(5)
.forks(1)
.jvmArgs("-server", "-Xms2048m", "-Xmx2048m")
.build();
new Runner(opt).run();
}
}